In the previous chapters, we introduced the environment setting of libtorch, common operations of libtorch tensor, simple MLP, CNN and LSTM model construction, and the use of data loading classes. In this chapter, we will take the image classification task as an example to introduce in detail how to train an image classifier using C++.
This article takes VGG as an example, illustrating the model building and training of Libtorch compared with pytorch. And the most important, loads pre-training (from ImageNet) weights. The VGG model is the 2014 ImageNet classification champion. Due to the development of subsequent deep learning, some components, such as batchnorm, have been added to form some new variants. This article takes vgg16bn as an example to introduce, vgg16bn is vgg16 with some batchnorm layers.
First, we introduce the source code of the model in pytorch. The official VGG model code is provided in torchvision.models.VGG of pytorch. Copy directly to analyze:
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return modelCompared with the current complex model, the VGG model has a simpler structure, which is a simple stack of multiple convolutions + downsampling, followed by a three-layer MLP. The VGG model class in the code has three member functions: an initialization function __init__, a forward propagation function forward, and a weight initialization function. There is a function make_layers outside the class to generate the CNN backbone and returns an nn.Sequential object.
Open the python editor (or IDE, with pytorch programming experience by default). Enter the following code:
from torchvision.models import vgg16,vgg16_bn
model = vgg16_bn(pretrained=True)
for k,v in model.named_parameters():
print(k)It is found that the name of each layer of the model (the weight layer, excluding the activation function layer or others alike) is printed. The printed layer names are as follows:
features.0.weight
features.0.bias
features.1.weight
features.1.bias
features.3.weight
features.3.bias
features.4.weight
features.4.bias
features.7.weight
features.7.bias
features.8.weight
features.8.bias
features.10.weight
features.10.bias
features.11.weight
features.11.bias
features.14.weight
features.14.bias
features.15.weight
features.15.bias
features.17.weight
features.17.bias
features.18.weight
features.18.bias
features.20.weight
features.20.bias
features.21.weight
features.21.bias
features.24.weight
features.24.bias
features.25.weight
features.25.bias
features.27.weight
features.27.bias
features.28.weight
features.28.bias
features.30.weight
features.30.bias
features.31.weight
features.31.bias
features.34.weight
features.34.bias
features.35.weight
features.35.bias
features.37.weight
features.37.bias
features.38.weight
features.38.bias
features.40.weight
features.40.bias
features.41.weight
features.41.bias
classifier.0.weight
classifier.0.bias
classifier.3.weight
classifier.3.bias
classifier.6.weight
classifier.6.bias
Well, not very long. This step is very important for subsequent model building and weights loading, because the torch model loading weights require a one-to-one correspondence with the name of the weight layer. If the weight layer name provided by the model in the code is inconsistent with the name of the weight, an error will occur.
Analyzing the name printed by the model, you will find that there are only features, classifier, weight, bias and numbers. Refer to initialization function __init__ of the previous official code. There are self.classifer and self.features inside the function, it is easy to get the naming rule of the internal layer name of the pytorch model. Weight and bias correspond to self.conv and self.bias in the conv layer. Dots and numbers indicate the sequence number in nn.Sequential.
Next, we will build a vgg16bn in C++ that is exactly the same as pytorch. If they are inconsistent, model training and prediction will be not affected, but the initialization state will be different. After the model loads the weights trained from the ImageNet data set, the training convergence speed and accuracy after convergence will be much better.
The first thing is to be done in the .h file, a conv_options determines the convolution hyperparameters, because it is commonly used, it is inlined. The maxpool_options function determines the hyperparameters of MaxPool2d. Then define a make_features function consistent with pytorch, and then declare initialization and forward propagation functions consistent with pytorch in the VGG class. Finally, there is a vgg16bn function, which returns the vgg16bn model.
//Consistent with the previous chapter, define a function to determine conv hyperparameters
inline torch::nn::Conv2dOptions conv_options(int64_t in_planes, int64_t out_planes, int64_t kerner_size,
int64_t stride = 1, int64_t padding = 0, bool with_bias = false) {
torch::nn::Conv2dOptions conv_options = torch::nn::Conv2dOptions(in_planes, out_planes, kerner_size);
conv_options.stride(stride);
conv_options.padding(padding);
conv_options.bias(with_bias);
return conv_options;
}
//Following the conv_options above, define a function to determine the hyperparameters of MaxPool2d
inline torch::nn::MaxPool2dOptions maxpool_options(int kernel_size, int stride){
torch::nn::MaxPool2dOptions maxpool_options(kernel_size);
maxpool_options.stride(stride);
return maxpool_options;
}
//Corresponding to the make_features function in pytorch, returns the CNN body, which is a torch::nn::Sequential object
torch::nn::Sequential make_features(std::vector<int> &cfg, bool batch_norm);
//The declaration of the VGG class, including initialization and forward propagation
class VGGImpl: public torch::nn::Module
{
private:
torch::nn::Sequential features_{nullptr};
torch::nn::AdaptiveAvgPool2d avgpool{nullptr};
torch::nn::Sequential classifier;
public:
VGGImpl(std::vector<int> &cfg, int num_classes = 1000, bool batch_norm = false);
torch::Tensor forward(torch::Tensor x);
};
TORCH_MODULE(VGG);
//vgg16bn
VGG vgg16bn(int num_classes);The content of the .cpp file is as follows:
torch::nn::Sequential make_features(std::vector<int> &cfg, bool batch_norm){
torch::nn::Sequential features;
int in_channels = 3;
for(auto v : cfg){
if(v==-1){
features->push_back(torch::nn::MaxPool2d(maxpool_options(2,2)));
}
else{
auto conv2d = torch::nn::Conv2d(conv_options(in_channels,v,3,1,1));
features->push_back(conv2d);
if(batch_norm){
features->push_back(torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(v)));
}
features->push_back(torch::nn::ReLU(torch::nn::ReLUOptions(true)));
in_channels = v;
}
}
return features;
}
VGGImpl::VGGImpl(std::vector<int> &cfg, int num_classes, bool batch_norm){
features_ = make_features(cfg,batch_norm);
avgpool = torch::nn::AdaptiveAvgPool2d(torch::nn::AdaptiveAvgPool2dOptions(7));
classifier->push_back(torch::nn::Linear(torch::nn::LinearOptions(512 * 7 * 7, 4096)));
classifier->push_back(torch::nn::ReLU(torch::nn::ReLUOptions(true)));
classifier->push_back(torch::nn::Dropout());
classifier->push_back(torch::nn::Linear(torch::nn::LinearOptions(4096, 4096)));
classifier->push_back(torch::nn::ReLU(torch::nn::ReLUOptions(true)));
classifier->push_back(torch::nn::Dropout());
classifier->push_back(torch::nn::Linear(torch::nn::LinearOptions(4096, num_classes)));
features_ = register_module("features",features_);
classifier = register_module("classifier",classifier);
}
torch::Tensor VGGImpl::forward(torch::Tensor x){
x = features_->forward(x);
x = avgpool(x);
x = torch::flatten(x,1);
x = classifier->forward(x);
return torch::log_softmax(x, 1);
}
VGG vgg16bn(int num_classes){
std::vector<int> cfg_dd = {64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1};
VGG vgg = VGG(cfg_dd,num_classes,true);
return vgg;
}The declaration of tuples in C++ will be too long if there are too much members. Lists or vectors only accept data of the same type.So, the original 'M' in cfg in pytorch is changed to -1.
It should be noted that when naming different layers of the model, only register_module names the features and classifiers in the code, which is consistent with pytorch.
Let's check whether the model defined by our c++ is completely consistent with pytorch. Instantiate a VGG object in the main function, and then print the name of each layer, the code is as follows:
std::vector<int> cfg_16bn = {64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1};
auto vgg16bn = VGG(cfg_16bn,1000,true);
auto dict16bn = vgg16bn->named_parameters();
for (auto n = dict16bn.begin(); n != dict16bn.end(); n++)
{
std::cout<<(*n).key()<<std::endl;
}It can be found that the name of each layer is exactly the same as the name of the internal layer of the model in pytorch. In this way, we save the model weights of pytorch and load them into c++.
To save the weight of the pytorch model, you cannot directly save the model with torch.save, so the saved model cannot be loaded by C++. We use the torch.jit.script model commonly used during deployment to save. The python save weight code is as follows:
import torch
from torchvision.models import vgg16,vgg16_bn
model=model.to(torch.device("cpu"))
model.eval()
var=torch.ones((1,3,224,224))
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("vgg16bn.pt")In this way, the weights of the convolutional layer, normalization layer, and linear layer of the model are saved in the .pt file. Now try to load it into c++. The loading code in c++ is relatively simple, try loading directly after the defined vgg16bn model:
std::vector<int> cfg_16bn = {64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1};
auto vgg16bn = VGG(cfg_16bn,1000,true);
torch::load(vgg16bn,"your path to vgg16bn.pt");If the codes are interrupted in the following function, the possible reasons are:
- The model was saved incorrectly and could not be loaded correctly
- The path is wrong, not pointing correctly (maybe very large)
- The model defined in c++ is inconsistent with the one defined in python. It is best to print it out and copy it to a file for comparison.
template <typename Value, typename... LoadFromArgs>
void load(Value& value, LoadFromArgs&&... args) {
serialize::InputArchive archive;
archive.load_from(std::forward<LoadFromArgs>(args)...);
archive >> value;
}Like Chapter 4, this chapter uses the insect classification data set provided by the pytorch official website. After downloading and decompressing, there are train and val folders, which contain two types of insect pictures. The data loading module code is the same as the previous chapter, so I won’t repeat it. If you’re interested, please refer to the previous chapters.
Once we finished the basic model definition, loading, data loading, we can then define a Classifier class. The main functions of this class are:
- Initialization: The model is mounted in the initialization, whether it is a cpu or a gpu; define the classifier and load the pre-trained weights to achieve better and faster training.
- Training: You can specify the number of training cycles of the classifier, the batch_size of the training, the learning rate, and the path where the model is saved.
- Prediction: The category predicted by the classifier can be returned by passing in the picture.
- Load weights.
The declaration of the class is simple:
class Classifier
{
private:
torch::Device device = torch::Device(torch::kCPU);
VGG vgg = VGG{nullptr};
public:
Classifier(int gpu_id = 0);
void Initialize(int num_classes, std::string pretrained_path);
void Train(int epochs, int batch_size, float learning_rate, std::string train_val_dir, std::string image_type, std::string save_path);
int Predict(cv::Mat &image);
void LoadWeight(std::string weight);
};The member function definition of the class is more complicated:
void Classifier::LoadWeight(std::string weight){
torch::load(vgg,weight);
vgg->to(device);
vgg->eval();
return;
}LoadWeight doesn't have much to talk about, it's very simple to load the model and set it to eval(). What needs attention is the initialization and training function. The initialization function cannot directly load the previously saved weights because the num_class of the last layer of the model is uncertain. And the training function should use train and val respectively, and pay attention to the loss setting and so on.
The first is the initialization function. The initialization function first defines a classifier vgg16bn corresponding to num_class, and then defines a vgg16bn with num_class=1000. Load the latter when loading, and then copy the weights to the former. The copying process is very essence and requires readers to think carefully. In addition to copying parameters, initialization will also be defined to load on the GPU corresponding to gpu_id, or set gpu_id to be less than 0 to load on the cpu.
Classifier::Classifier(int gpu_id)
{
if (gpu_id >= 0) {
device = torch::Device(torch::kCUDA, gpu_id);
}
else {
device = torch::Device(torch::kCPU);
}
}
void Classifier::Initialize(int _num_classes, std::string _pretrained_path){
std::vector<int> cfg_d = {64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1};
auto net_pretrained = VGG(cfg_d,1000,true);
vgg = VGG(cfg_d,_num_classes,true);
torch::load(net_pretrained, _pretrained_path);
torch::OrderedDict<std::string, at::Tensor> pretrained_dict = net_pretrained->named_parameters();
torch::OrderedDict<std::string, at::Tensor> model_dict = vgg->named_parameters();
for (auto n = pretrained_dict.begin(); n != pretrained_dict.end(); n++)
{
if (strstr((*n).key().data(), "classifier")) {
continue;
}
model_dict[(*n).key()] = (*n).value();
}
torch::autograd::GradMode::set_enabled(false); // make parameters copible
auto new_params = model_dict;
auto params = vgg->named_parameters(true );
auto buffers = vgg->named_buffers(true);
for (auto& val : new_params) {
auto name = val.key();
auto* t = params.find(name);
if (t != nullptr) {
t->copy_(val.value());
}
else {
t = buffers.find(name);
if (t != nullptr) {
t->copy_(val.value());
}
}
}
torch::autograd::GradMode::set_enabled(true);
try
{
vgg->to(device);
}
catch (const std::exception&e)
{
std::cout << e.what() << std::endl;
}
return;
}The training function uses train_loader and val_loader respectively. The former loads the pictures in the train folder for training, and the latter is used for evaluation. The training process defines the optimizer, loss function, etc.
void Classifier::Train(int num_epochs, int batch_size, float learning_rate, std::string train_val_dir, std::string image_type, std::string save_path){
std::string path_train = train_val_dir+ "\\train";
std::string path_val = train_val_dir + "\\val";
auto custom_dataset_train = dataSetClc(path_train, image_type).map(torch::data::transforms::Stack<>());
auto custom_dataset_val = dataSetClc(path_val, image_type).map(torch::data::transforms::Stack<>());
auto data_loader_train = torch::data::make_data_loader<torch::data::samplers::RandomSampler>(std::move(custom_dataset_train), batch_size);
auto data_loader_val = torch::data::make_data_loader<torch::data::samplers::RandomSampler>(std::move(custom_dataset_val), batch_size);
float loss_train = 0; float loss_val = 0;
float acc_train = 0.0; float acc_val = 0.0; float best_acc = 0.0;
for (size_t epoch = 1; epoch <= num_epochs; ++epoch) {
size_t batch_index_train = 0;
size_t batch_index_val = 0;
if (epoch == int(num_epochs / 2)) { learning_rate /= 10; }
torch::optim::Adam optimizer(vgg->parameters(), learning_rate); // learning rate
if (epoch < int(num_epochs / 8))
{
for (auto mm : vgg->named_parameters())
{
if (strstr(mm.key().data(), "classifier"))
{
mm.value().set_requires_grad(true);
}
else
{
mm.value().set_requires_grad(false);
}
}
}
else {
for (auto mm : vgg->named_parameters())
{
mm.value().set_requires_grad(true);
}
}
// traverse data_loader to generate batchs
for (auto& batch : *data_loader_train) {
auto data = batch.data;
auto target = batch.target.squeeze();
data = data.to(torch::kF32).to(device).div(255.0);
target = target.to(torch::kInt64).to(device);
optimizer.zero_grad();
// Execute the model
torch::Tensor prediction = vgg->forward(data);
auto acc = prediction.argmax(1).eq(target).sum();
acc_train += acc.template item<float>() / batch_size;
// compute loss
torch::Tensor loss = torch::nll_loss(prediction, target);
loss.backward();
// update weight
optimizer.step();
loss_train += loss.item<float>();
batch_index_train++;
std::cout << "Epoch: " << epoch << " |Train Loss: " << loss_train / batch_index_train << " |Train Acc:" << acc_train / batch_index_train << "\r";
}
std::cout << std::endl;
//validation
vgg->eval();
for (auto& batch : *data_loader_val) {
auto data = batch.data;
auto target = batch.target.squeeze();
data = data.to(torch::kF32).to(device).div(255.0);
target = target.to(torch::kInt64).to(device);
torch::Tensor prediction = vgg->forward(data);
// compute loss, cross-entropy loss
torch::Tensor loss = torch::nll_loss(prediction, target);
auto acc = prediction.argmax(1).eq(target).sum();
acc_val += acc.template item<float>() / batch_size;
loss_val += loss.item<float>();
batch_index_val++;
std::cout << "Epoch: " << epoch << " |Val Loss: " << loss_val / batch_index_val << " |Valid Acc:" << acc_val / batch_index_val << "\r";
}
std::cout << std::endl;
if (acc_val > best_acc) {
torch::save(vgg, save_path);
best_acc = acc_val;
}
loss_train = 0; loss_val = 0; acc_train = 0; acc_val = 0; batch_index_train = 0; batch_index_val = 0;
}
}The last is prediction. It returns the category and its confidence.
int Classifier::Predict(cv::Mat& image){
cv::resize(image, image, cv::Size(448, 448));
torch::Tensor img_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 });
img_tensor = img_tensor.to(device).unsqueeze(0).to(torch::kF32).div(255.0);
auto prediction = vgg->forward(img_tensor);
prediction = torch::softmax(prediction,1);
auto class_id = prediction.argmax(1);
int ans = int(class_id.item().toInt());
float prob = prediction[0][ans].item().toFloat();
return ans;
}A picture of training is posted:
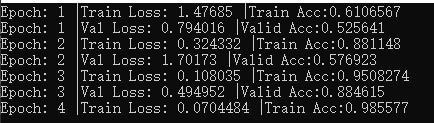 。
The parameter settings during training are as follows:
。
The parameter settings during training are as follows:
std::string vgg_path = "your path to vgg16_bn.pt";
std::string train_val_dir = "your path to hymenoptera_data";
Classifier classifier(0);
classifier.Initialize(2,vgg_path);
classifier.Train(300,4,0.0003,train_val_dir,".jpg","classifer.pt");In fact, when the number of cycles is set to 300, many previous cycles are doing fixed CNN migration learning (or finetune). You can set a smaller one to see what happens when you train all models directly, and think about why.