{kind=link}
{kind=link}
Code repository links to Reading this article requires basic pytorch programming experience and knowledge of the target detection framework. It doesn't need to be very deep, just a general understanding of the concept.
This chapter briefly introduces how to implement an object detector in C++, which has the functions of training and prediction. The segmentation model architecture of this article uses the yolov4-tiny structure, and the code structure refers to bubbliiiing yolov4-tiny. The c++ model shared in this article almost perfectly reproduces pytorch Version, and has a speed advantage, 30-40% speed increase.
Briefly introduce the yolov4-tiny model. The yolov4-tiny model is a lightweight version of version 4 in the YOLO (you only look once) series of models. Compared with yolov4, it sacrifices part of the accuracy to achieve a significant increase in speed. The yolov4_tiny model structure is shown in the figure (picture source from this):
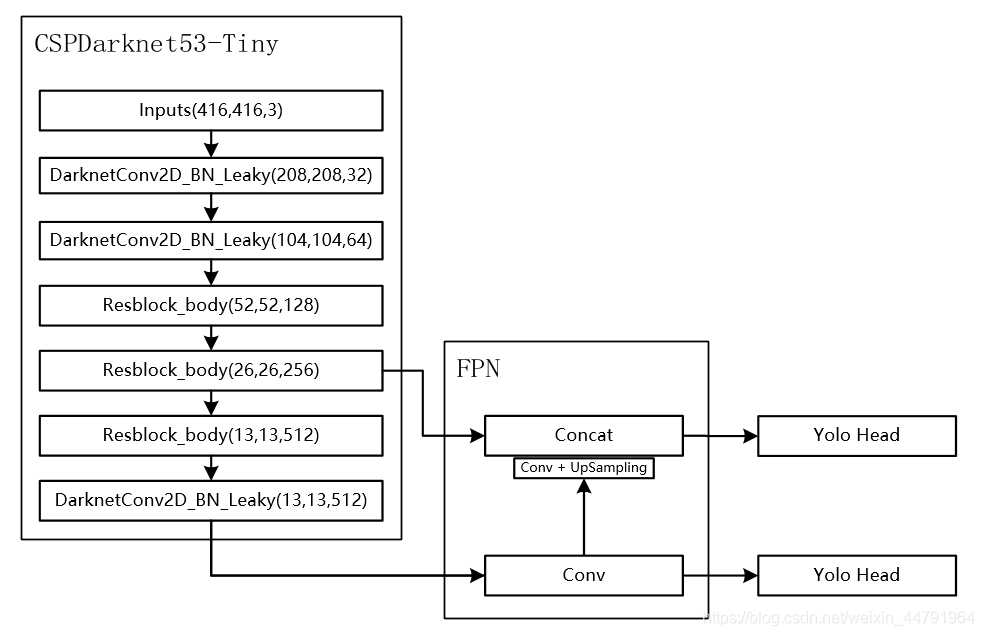 It can be found that the model structure is very simple, with CSPDarknet53-tiny as the backbone network, FPN as the neck, and Yolo head as the head. Finally, two feature layers are output, which are the feature maps down-sampled 32 times and 16 times from the original image. During training, we input the two feature maps into the loss calculation to calculate the loss, and then sum the losses (or average, whichever is good), and then do back propagation. When predicting, the decoded results of the two feature maps are combined and do NMS (non-maximum suppression).
It can be found that the model structure is very simple, with CSPDarknet53-tiny as the backbone network, FPN as the neck, and Yolo head as the head. Finally, two feature layers are output, which are the feature maps down-sampled 32 times and 16 times from the original image. During training, we input the two feature maps into the loss calculation to calculate the loss, and then sum the losses (or average, whichever is good), and then do back propagation. When predicting, the decoded results of the two feature maps are combined and do NMS (non-maximum suppression).
CSPDarknet53-tiny is a type of CSPNet. CSPNet was published in CVPR2019 and is a backbone network used to improve the detection performance of object detection models. Interested students can read the original article and generally understand the contribution of the paper. That is, the feature layer is cut into two pieces along the channel dimension, and the two pieces are convolved differently, and then joined together. Compared to directly comparing the original feature extraction for images, it can reduce the amount of calculations.
By default, I assume you have read the previous part of my libtorch series of tutorials, and directly post the code. The first is the basic unit, which is composed of Conv2d + BatchNorm2d + LeakyReLU.
//Conv2d + BatchNorm2d + LeakyReLU
class BasicConvImpl : public torch::nn::Module {
public:
BasicConvImpl(int in_channels, int out_channels, int kernel_size, int stride = 1);
torch::Tensor forward(torch::Tensor x);
private:
// Declare layers
torch::nn::Conv2d conv{ nullptr };
torch::nn::BatchNorm2d bn{ nullptr };
torch::nn::LeakyReLU acitivation{ nullptr };
}; TORCH_MODULE(BasicConv);
BasicConvImpl::BasicConvImpl(int in_channels, int out_channels, int kernel_size,
int stride) :
conv(conv_options(in_channels, out_channels, kernel_size, stride,
int(kernel_size / 2), 1, false)),
bn(torch::nn::BatchNorm2d(out_channels)),
acitivation(torch::nn::LeakyReLU(torch::nn::LeakyReLUOptions().negative_slope(0.1)))
{
register_module("conv", conv);
register_module("bn", bn);
}
torch::Tensor BasicConvImpl::forward(torch::Tensor x)
{
x = conv->forward(x);
x = bn->forward(x);
x = acitivation(x);
return x;
}This layer is used as a basic module and will be used as a basic block for building blocks in the later stage to build yolo4_tiny.
Then there is the Resblock_body module,
class Resblock_bodyImpl : public torch::nn::Module {
public:
Resblock_bodyImpl(int in_channels, int out_channels);
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
int out_channels;
BasicConv conv1{ nullptr };
BasicConv conv2{ nullptr };
BasicConv conv3{ nullptr };
BasicConv conv4{ nullptr };
torch::nn::MaxPool2d maxpool{ nullptr };
}; TORCH_MODULE(Resblock_body);
Resblock_bodyImpl::Resblock_bodyImpl(int in_channels, int out_channels) {
this->out_channels = out_channels;
conv1 = BasicConv(in_channels, out_channels, 3);
conv2 = BasicConv(out_channels / 2, out_channels / 2, 3);
conv3 = BasicConv(out_channels / 2, out_channels / 2, 3);
conv4 = BasicConv(out_channels, out_channels, 1);
maxpool = torch::nn::MaxPool2d(maxpool_options(2, 2));
register_module("conv1", conv1);
register_module("conv2", conv2);
register_module("conv3", conv3);
register_module("conv4", conv4);
}
std::vector<torch::Tensor> Resblock_bodyImpl::forward(torch::Tensor x) {
auto c = out_channels;
x = conv1->forward(x);
auto route = x;
x = torch::split(x, c / 2, 1)[1];
x = conv2->forward(x);
auto route1 = x;
x = conv3->forward(x);
x = torch::cat({ x, route1 }, 1);
x = conv4->forward(x);
auto feat = x;
x = torch::cat({ route, x }, 1);
x = maxpool->forward(x);
return std::vector<torch::Tensor>({ x,feat });
}The main body of the backbone network:
class CSPdarknet53_tinyImpl : public torch::nn::Module
{
public:
CSPdarknet53_tinyImpl();
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
BasicConv conv1{ nullptr };
BasicConv conv2{ nullptr };
Resblock_body resblock_body1{ nullptr };
Resblock_body resblock_body2{ nullptr };
Resblock_body resblock_body3{ nullptr };
BasicConv conv3{ nullptr };
int num_features = 1;
}; TORCH_MODULE(CSPdarknet53_tiny);
CSPdarknet53_tinyImpl::CSPdarknet53_tinyImpl() {
conv1 = BasicConv(3, 32, 3, 2);
conv2 = BasicConv(32, 64, 3, 2);
resblock_body1 = Resblock_body(64, 64);
resblock_body2 = Resblock_body(128, 128);
resblock_body3 = Resblock_body(256, 256);
conv3 = BasicConv(512, 512, 3);
register_module("conv1", conv1);
register_module("conv2", conv2);
register_module("resblock_body1", resblock_body1);
register_module("resblock_body2", resblock_body2);
register_module("resblock_body3", resblock_body3);
register_module("conv3", conv3);
}
std::vector<torch::Tensor> CSPdarknet53_tinyImpl::forward(torch::Tensor x) {
// 416, 416, 3 -> 208, 208, 32 -> 104, 104, 64
x = conv1(x);
x = conv2(x);
// 104, 104, 64 -> 52, 52, 128
x = resblock_body1->forward(x)[0];
// 52, 52, 128 -> 26, 26, 256
x = resblock_body2->forward(x)[0];
// 26, 26, 256->xΪ13, 13, 512
# // -> feat1Ϊ26,26,256
auto res_out = resblock_body3->forward(x);
x = res_out[0];
auto feat1 = res_out[1];
// 13, 13, 512 -> 13, 13, 512
x = conv3->forward(x);
auto feat2 = x;
return std::vector<torch::Tensor>({ feat1, feat2 });
}So far, the backbone network in yolo4_tiny has been built. Next, we will build the yolo4_tiny model.
The feature map obtained by the backbone network will be passed through the FPN and it requires an up-sampling module.
//conv+upsample
class UpsampleImpl : public torch::nn::Module {
public:
UpsampleImpl(int in_channels, int out_channels);
torch::Tensor forward(torch::Tensor x);
private:
// Declare layers
torch::nn::Sequential upsample = torch::nn::Sequential();
}; TORCH_MODULE(Upsample);
UpsampleImpl::UpsampleImpl(int in_channels, int out_channels)
{
upsample = torch::nn::Sequential(
BasicConv(in_channels, out_channels, 1)
//torch::nn::Upsample(torch::nn::UpsampleOptions().scale_factor(std::vector<double>({ 2 })).mode(torch::kNearest).align_corners(false))
);
register_module("upsample", upsample);
}
torch::Tensor UpsampleImpl::forward(torch::Tensor x)
{
x = upsample->forward(x);
x = at::upsample_nearest2d(x, { x.sizes()[2] * 2 , x.sizes()[3] * 2 });
return x;
}Then is yolo_head module:
torch::nn::Sequential yolo_head(std::vector<int> filters_list, int in_filters);
torch::nn::Sequential yolo_head(std::vector<int> filters_list, int in_filters) {
auto m = torch::nn::Sequential(BasicConv(in_filters, filters_list[0], 3),
torch::nn::Conv2d(conv_options(filters_list[0], filters_list[1], 1)));
return m;
}And yolo_body:
class YoloBody_tinyImpl : public torch::nn::Module {
public:
YoloBody_tinyImpl(int num_anchors, int num_classes);
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
// Declare layers
CSPdarknet53_tiny backbone{ nullptr };
BasicConv conv_for_P5{ nullptr };
Upsample upsample{ nullptr };
torch::nn::Sequential yolo_headP5{ nullptr };
torch::nn::Sequential yolo_headP4{ nullptr };
}; TORCH_MODULE(YoloBody_tiny);
YoloBody_tinyImpl::YoloBody_tinyImpl(int num_anchors, int num_classes) {
backbone = CSPdarknet53_tiny();
conv_for_P5 = BasicConv(512, 256, 1);
yolo_headP5 = yolo_head({ 512, num_anchors * (5 + num_classes) }, 256);
upsample = Upsample(256, 128);
yolo_headP4 = yolo_head({ 256, num_anchors * (5 + num_classes) }, 384);
register_module("backbone", backbone);
register_module("conv_for_P5", conv_for_P5);
register_module("yolo_headP5", yolo_headP5);
register_module("upsample", upsample);
register_module("yolo_headP4", yolo_headP4);
}
std::vector<torch::Tensor> YoloBody_tinyImpl::forward(torch::Tensor x) {
//return feat1 with shape of {26,26,256} and feat2 of {13, 13, 512}
auto backbone_out = backbone->forward(x);
auto feat1 = backbone_out[0];
auto feat2 = backbone_out[1];
//13,13,512 -> 13,13,256
auto P5 = conv_for_P5->forward(feat2);
//13, 13, 256 -> 13, 13, 512 -> 13, 13, 255
auto out0 = yolo_headP5->forward(P5);
//13,13,256 -> 13,13,128 -> 26,26,128
auto P5_Upsample = upsample->forward(P5);
//26, 26, 256 + 26, 26, 128 -> 26, 26, 384
auto P4 = torch::cat({ P5_Upsample, feat1 }, 1);
//26, 26, 384 -> 26, 26, 256 -> 26, 26, 255
auto out1 = yolo_headP4->forward(P4);
return std::vector<torch::Tensor>({ out0, out1 });
}As the code is written to this step, you can find that it is basically a migration of pytorch code to libtorch. Except for a few bugs that need to be fixed, most of them are simply migrated to C++.
Generate the torchscript model as in the previous chapter. A coco training version is provided in bubbliiiing yolov4-tiny, and the .pt file is generated by the following code:
import torch
from torchsummary import summary
import numpy as np
from nets.yolo4_tiny import YoloBody
from train import get_anchors, get_classes,YOLOLoss
device = torch.device('cpu')
model = YoloBody(3,80).to(device)
model_path = "model_data/yolov4_tiny_weights_coco.pth"
print('Loading weights into state dict...')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=torch.device("cpu"))
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
#generating .pt file
model=model.to(torch.device("cpu"))
model.eval()
var=torch.ones((1,3,416,416))
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("yolo4_tiny.pt")Then use the following code in C++ to test whether it can be loaded correctly:
auto model = YoloBody_tiny(3, 80);
torch::load(model, "weights/yolo4_tiny.pt");The execution with no errors means that the loading is successful.
The prediction needs to decode the tensor output by the YOLO4_tiny model. According to the source code, we write the C++ version of the decoding function. At this time, you will find that libtorch tutorials chapter 2 is pretty important.
torch::Tensor DecodeBox(torch::Tensor input, torch::Tensor anchors, int num_classes, int img_size[])
{
int num_anchors = anchors.sizes()[0];
int bbox_attrs = 5 + num_classes;
int batch_size = input.sizes()[0];
int input_height = input.sizes()[2];
int input_width = input.sizes()[3];
//416 / 13 = 32
auto stride_h = img_size[1] / input_height;
auto stride_w = img_size[0] / input_width;
//Adjust the size of the prior frame to the size of the feature layer
//Calculate the corresponding width and height of the a priori box on the feature layer
auto scaled_anchors = anchors.clone();
scaled_anchors.select(1, 0) = scaled_anchors.select(1, 0) / stride_w;
scaled_anchors.select(1, 1) = scaled_anchors.select(1, 1) / stride_h;
//bs, 3 * (5 + num_classes), 13, 13->bs, 3, 13, 13, (5 + num_classes)
//cout << "begin view"<<input.sizes()<<endl;
auto prediction = input.view({ batch_size, num_anchors,bbox_attrs, input_height, input_width }).permute({ 0, 1, 3, 4, 2 }).contiguous();
//cout << "end view" << endl;
//Adjustment parameters for the center position of the a priori box
auto x = torch::sigmoid(prediction.select(-1, 0));
auto y = torch::sigmoid(prediction.select(-1, 1));
//The width and height adjustment parameters of the a priori box
auto w = prediction.select(-1, 2); // Width
auto h = prediction.select(-1, 3); // Height
//Get confidence, whether there is an object
auto conf = torch::sigmoid(prediction.select(-1, 4));
//Category confidence
auto pred_cls = torch::sigmoid(prediction.narrow(-1, 5, num_classes));// Cls pred.
auto LongType = x.clone().to(torch::kLong).options();
auto FloatType = x.options();
//Generate grid, a priori box center, upper left corner of the grid batch_size, 3, 13, 13
auto grid_x = torch::linspace(0, input_width - 1, input_width).repeat({ input_height, 1 }).repeat(
{ batch_size * num_anchors, 1, 1 }).view(x.sizes()).to(FloatType);
auto grid_y = torch::linspace(0, input_height - 1, input_height).repeat({ input_width, 1 }).t().repeat(
{ batch_size * num_anchors, 1, 1 }).view(y.sizes()).to(FloatType);
//Generate the width and height of the a priori box
auto anchor_w = scaled_anchors.to(FloatType).narrow(1, 0, 1);
auto anchor_h = scaled_anchors.to(FloatType).narrow(1, 1, 1);
anchor_w = anchor_w.repeat({ batch_size, 1 }).repeat({ 1, 1, input_height * input_width }).view(w.sizes());
anchor_h = anchor_h.repeat({ batch_size, 1 }).repeat({ 1, 1, input_height * input_width }).view(h.sizes());
//Calculate the adjusted a priori box center and width and height
auto pred_boxes = torch::randn_like(prediction.narrow(-1, 0, 4)).to(FloatType);
pred_boxes.select(-1, 0) = x + grid_x;
pred_boxes.select(-1, 1) = y + grid_y;
pred_boxes.select(-1, 2) = w.exp() * anchor_w;
pred_boxes.select(-1, 3) = h.exp() * anchor_h;
//Used to adjust the output to a size relative to 416x416
std::vector<int> scales{ stride_w, stride_h, stride_w, stride_h };
auto _scale = torch::tensor(scales).to(FloatType);
//cout << pred_boxes << endl;
//cout << conf << endl;
//cout << pred_cls << endl;
pred_boxes = pred_boxes.view({ batch_size, -1, 4 }) * _scale;
conf = conf.view({ batch_size, -1, 1 });
pred_cls = pred_cls.view({ batch_size, -1, num_classes });
auto output = torch::cat({ pred_boxes, conf, pred_cls }, -1);
return output;
}In addition, the output also needs to be non-maximum suppression.
std::vector<int> nms_libtorch(torch::Tensor bboxes, torch::Tensor scores, float thresh) {
auto x1 = bboxes.select(-1, 0);
auto y1 = bboxes.select(-1, 1);
auto x2 = bboxes.select(-1, 2);
auto y2 = bboxes.select(-1, 3);
auto areas = (x2 - x1)*(y2 - y1); //[N, ] bbox area
auto tuple_sorted = scores.sort(0, true); //sorting
auto order = std::get<1>(tuple_sorted);
std::vector<int> keep;
while (order.numel() > 0) {// torch.numel() return elements nums
if (order.numel() == 1) {// keep
auto i = order.item();
keep.push_back(i.toInt());
break;
}
else {
auto i = order[0].item();
keep.push_back(i.toInt());
}
auto order_mask = order.narrow(0, 1, order.size(-1) - 1);
x1.index({ order_mask });
x1.index({ order_mask }).clamp(x1[keep.back()].item().toFloat(), 1e10);
auto xx1 = x1.index({ order_mask }).clamp(x1[keep.back()].item().toFloat(), 1e10);// [N - 1, ]
auto yy1 = y1.index({ order_mask }).clamp(y1[keep.back()].item().toFloat(), 1e10);
auto xx2 = x2.index({ order_mask }).clamp(0, x2[keep.back()].item().toFloat());
auto yy2 = y2.index({ order_mask }).clamp(0, y2[keep.back()].item().toFloat());
auto inter = (xx2 - xx1).clamp(0, 1e10) * (yy2 - yy1).clamp(0, 1e10);// [N - 1, ]
auto iou = inter / (areas[keep.back()] + areas.index({ order.narrow(0,1,order.size(-1) - 1) }) - inter);//[N - 1, ]
auto idx = (iou <= thresh).nonzero().squeeze();
if (idx.numel() == 0) {
break;
}
order = order.index({ idx + 1 });
}
return keep;
}
std::vector<torch::Tensor> non_maximum_suppression(torch::Tensor prediction, int num_classes, float conf_thres, float nms_thres) {
prediction.select(-1, 0) -= prediction.select(-1, 2) / 2;
prediction.select(-1, 1) -= prediction.select(-1, 3) / 2;
prediction.select(-1, 2) += prediction.select(-1, 0);
prediction.select(-1, 3) += prediction.select(-1, 1);
std::vector<torch::Tensor> output;
for (int image_id = 0; image_id < prediction.sizes()[0]; image_id++) {
auto image_pred = prediction[image_id];
auto max_out_tuple = torch::max(image_pred.narrow(-1, 5, num_classes), -1, true);
auto class_conf = std::get<0>(max_out_tuple);
auto class_pred = std::get<1>(max_out_tuple);
auto conf_mask = (image_pred.select(-1, 4) * class_conf.select(-1, 0) >= conf_thres).squeeze();
image_pred = image_pred.index({ conf_mask }).to(torch::kFloat);
class_conf = class_conf.index({ conf_mask }).to(torch::kFloat);
class_pred = class_pred.index({ conf_mask }).to(torch::kFloat);
if (!image_pred.sizes()[0]) {
output.push_back(torch::full({ 1, 7 }, 0));
continue;
}
//obtans (x1, y1, x2, y2, obj_conf, class_conf, class_pred)
auto detections = torch::cat({ image_pred.narrow(-1,0,5), class_conf, class_pred }, 1);
std::vector<torch::Tensor> img_classes;
for (int m = 0, len = detections.size(0); m < len; m++)
{
bool found = false;
for (size_t n = 0; n < img_classes.size(); n++)
{
auto ret = (detections[m][6] == img_classes[n]);
if (torch::nonzero(ret).size(0) > 0)
{
found = true;
break;
}
}
if (!found) img_classes.push_back(detections[m][6]);
}
std::vector<torch::Tensor> temp_class_detections;
for (auto c : img_classes) {
auto detections_class = detections.index({ detections.select(-1,-1) == c });
auto keep = nms_libtorch(detections_class.narrow(-1, 0, 4), detections_class.select(-1, 4)*detections_class.select(-1, 5), nms_thres);
std::vector<torch::Tensor> temp_max_detections;
for (auto v : keep) {
temp_max_detections.push_back(detections_class[v]);
}
auto max_detections = torch::cat(temp_max_detections, 0);
temp_class_detections.push_back(max_detections);
}
auto class_detections = torch::cat(temp_class_detections, 0);
output.push_back(class_detections);
}
return output;
}After these functions are ready, write the prediction function:
void show_bbox_coco(cv::Mat image, torch::Tensor bboxes, int nums) {
int font_face = cv::FONT_HERSHEY_COMPLEX;
double font_scale = 0.4;
int thickness = 1;
float* bbox = new float[bboxes.size(0)]();
std::cout << bboxes << std::endl;
memcpy(bbox, bboxes.cpu().data_ptr(), bboxes.size(0) * sizeof(float));
for (int i = 0; i < bboxes.size(0); i = i + 7)
{
cv::rectangle(image, cv::Rect(bbox[i + 0], bbox[i + 1], bbox[i + 2] - bbox[i + 0], bbox[i + 3] - bbox[i + 1]), cv::Scalar(0, 0, 255));
cv::Point origin;
origin.x = bbox[i + 0];
origin.y = bbox[i + 1] + 8;
cv::putText(image, std::to_string(int(bbox[i + 6])), origin, font_face, font_scale, cv::Scalar(0, 0, 255), thickness, 1, 0);
}
delete bbox;
cv::imshow("test", image);
cv::waitKey(0);
cv::destroyAllWindows();
}
void Predict(YoloBody_tiny detector, cv::Mat image, bool show, float conf_thresh, float nms_thresh) {
int origin_width = image.cols;
int origin_height = image.rows;
cv::resize(image, image, { 416,416 });
auto img_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte);
img_tensor = img_tensor.permute({ 2, 0, 1 }).unsqueeze(0).to(torch::kFloat) / 255.0;
float anchor[12] = { 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 };
auto anchors_ = torch::from_blob(anchor, { 6,2 }, torch::TensorOptions(torch::kFloat32));
int image_size[2] = { 416,416 };
img_tensor = img_tensor.cuda();
auto outputs = detector->forward(img_tensor);
std::vector<torch::Tensor> output_list = {};
auto tensor_input = outputs[1];
auto output_decoded = DecodeBox(tensor_input, anchors_.narrow(0, 0, 3), 80, image_size);
output_list.push_back(output_decoded);
tensor_input = outputs[0];
output_decoded = DecodeBox(tensor_input, anchors_.narrow(0, 3, 3), 80, image_size);
output_list.push_back(output_decoded);
//std::cout << tensor_input << anchors_.narrow(0, 3, 3);
auto output = torch::cat(output_list, 1);
auto detection = non_maximum_suppression(output, 80, conf_thresh, nms_thresh);
float w_scale = float(origin_width) / 416;
float h_scale = float(origin_height) / 416;
for (int i = 0; i < detection.size(); i++) {
for (int j = 0; j < detection[i].size(0) / 7; j++)
{
detection[i].select(0, 7 * j + 0) *= w_scale;
detection[i].select(0, 7 * j + 1) *= h_scale;
detection[i].select(0, 7 * j + 2) *= w_scale;
detection[i].select(0, 7 * j + 3) *= h_scale;
}
}
cv::resize(image, image, { origin_width,origin_height });
if (show)
show_bbox_coco(image, detection[0], 80);
return;
}Use a picture in the VOC data set to test the accuracy of the function. Use the above code directly to test the .pt file, for example, enter the following code:
cv::Mat image = cv::imread("2007_005331.jpg");
auto model = YoloBody_tiny(3, 80);
torch::load(model, "weights/yolo4_tiny.pt");
model->to(torch::kCUDA);
Predict(model, image, true, 0.1, 0.3);The picture used is as shown below

It will be found that the forecast results are as follows:

The result analysis has the following two conclusions:
- The detection box is output, and the prediction function is likely to be correct;
- There are some false detections. Increasing the confidence threshold may be improved, but the detection will be missed. This is caused by the inconsistency between the preprocessing strategy used in the training of the .pt file and the preprocessing strategy used in the code prediction of this article.
Use the same preprocessing method of training and prediction to process the picture, and the result should be much better. The following is a picture, using coco pre-training weights for migration learning, only training yolo_head, after training the voc data set for one cycle.

Continue training, data augmentation, training all weights should improve the results even more.
There are more training codes, and the blog will not introduce it. You can directly refer to the source codes of this project and if it helps you, don't hesitate to star.